《美洽调用乱码频发?别让乱码“搅黄”你的客户体验!》
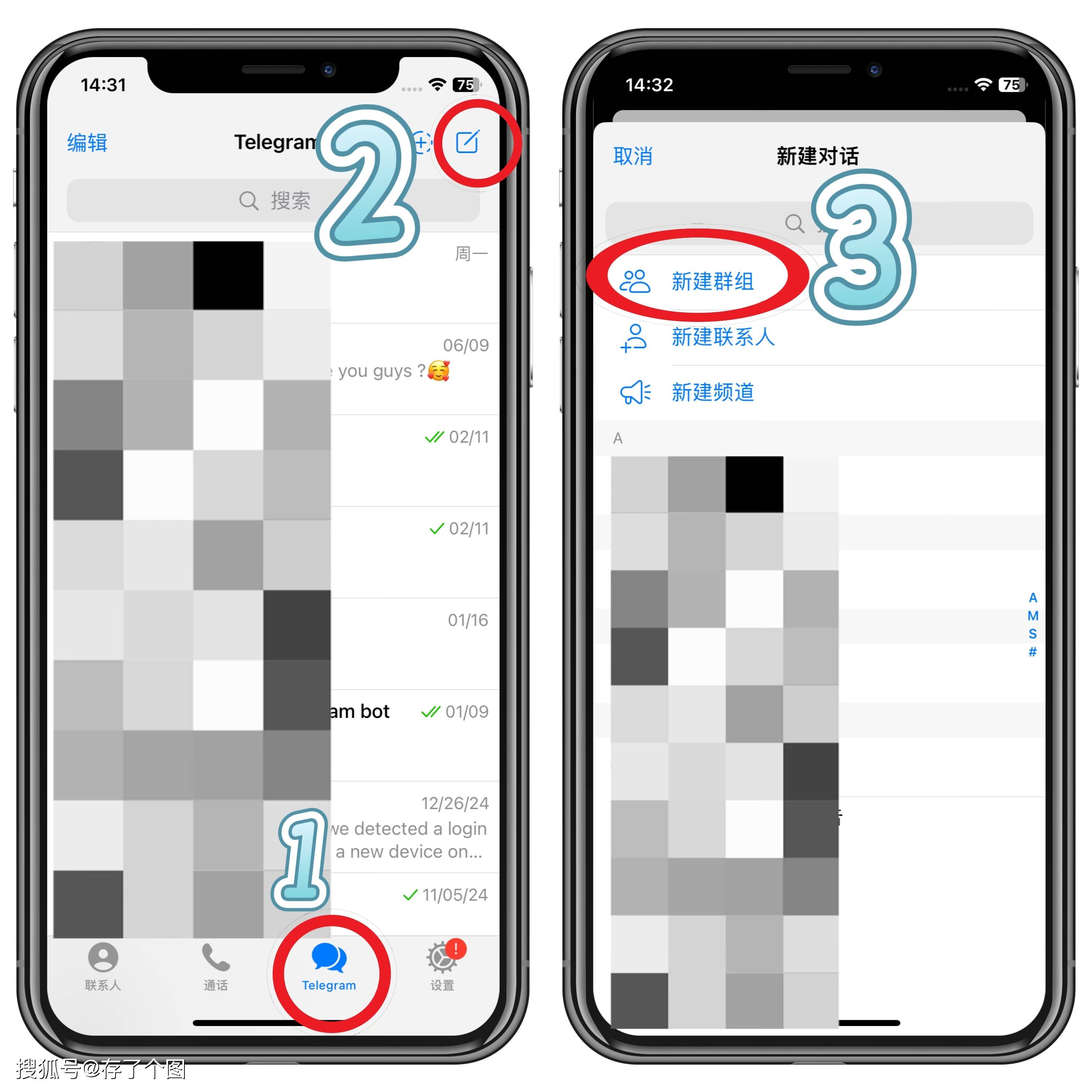
美洽调用乱码:技术解析与应对策略
在数字化客户服务领域,美洽作为一款流行的在线客服系统,其稳定性和易用性备受企业青睐。然而,在实际集成与调用过程中,部分开发者或运维人员可能会遭遇一个令人头疼的问题——**接口返回或显示乱码**。这类问题不仅影响数据的正常解析与展示,更可能直接导致客户沟通链路中断,损害用户体验。本文将深入探讨美洽调用乱码的常见成因、排查思路及系统性解决方案。乱码问题的核心成因剖析
乱码的本质是字符编码不一致所导致的信息失真。在美洽的API调用、消息推送或页面嵌入场景中,乱码通常源于以下几个技术环节的失配: 首先,**字符编码声明不一致**是最常见的原因。例如,美洽服务器默认使用UTF-8编码传输数据,而调用方(如企业自建网站或应用程序)在接收或处理数据时,若未明确指定使用UTF-8,或使用了GBK、ISO-8859-1等其他编码格式进行解码,就会产生中文字符等非ASCII字符的乱码现象。 其次,**数据传输过程中的编码转换错误**也可能引发问题。特别是在通过Webhook接收美洽的消息推送时,如果中间代理服务器(如Nginx、Apache)未正确配置字符编码,或在代码中进行不必要的字符串编码转换,都可能导致乱码产生。 此外,**数据库或缓存层的编码设置**同样不容忽视。若企业将美洽的会话记录存储到自建数据库中,而数据库、数据表或字段的字符集与美洽传输的编码不匹配,在读写过程中就会出现乱码。甚至浏览器的页面元标签(如``)设置错误,也会影响前端页面的正常显示。系统性排查与诊断步骤
面对乱码问题,建议遵循由表及里、从简到繁的排查路径: 第一步,**定位乱码发生的具体环节**。确认乱码是出现在API响应中、数据库存储里,还是前端页面上。可通过抓包工具(如Charles、Fiddler)直接查看美洽API返回的原始数据,若原始数据正常,则问题大概率出在接收方的处理或展示环节。 第二步,**检查编码配置的统一性**。确保调用美洽API的代码中,请求头(如`Content-Type: application/json; charset=utf-8`)与响应处理均明确使用UTF-8编码。同时,验证自身服务器环境、数据库连接及前端页面的字符集声明是否一致为UTF-8。 第三步,**验证数据流的完整性**。检查是否有中间件(如负载均衡器、网关)对数据进行了重新编码或过滤。对于Webhook推送,可对比美洽发送的原始请求体与接收端实际获取的数据,确认传输过程无篡改。行之有效的解决方案与最佳实践
基于上述成因,解决乱码问题需采取针对性措施: 在**开发集成阶段**,强制规范所有与美洽交互的接口均使用UTF-8编码。在代码中,对HTTP请求和响应显式设置字符集,例如在Java中使用`String.getBytes("UTF-8")`,在Python中使用`response.content.decode('utf-8')`。同时,在前端嵌入美洽聊天窗口时,确保页面包含``标签。 在**服务器与数据库层面**,统一环境编码。检查Linux服务器的`/etc/sysconfig/i18n`或`locale`设置,确保语言环境支持UTF-8。对于MySQL等数据库,创建数据库时指定`CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci`,以完整支持所有Unicode字符(包括表情符号)。 在**运维监控层面**,建立字符编码的检查机制。可在关键数据流转节点加入编码验证日志,一旦发现非UTF-8编码数据及时告警。对于历史已产生的乱码数据,可通过编写转换脚本,在明确原始编码的前提下进行批量转码修复。 总之,美洽调用乱码虽是一个典型的编码问题,但其解决需要开发、运维乃至数据库管理员的协同关注。通过建立统一的编码规范、实施严格的配置管理,并辅以主动的监控手段,企业完全可以从根本上杜绝乱码的产生,确保客户服务系统的顺畅与专业。在数字化沟通日益重要的今天,细节处的技术稳定性,正是提升客户信任与满意度的基石。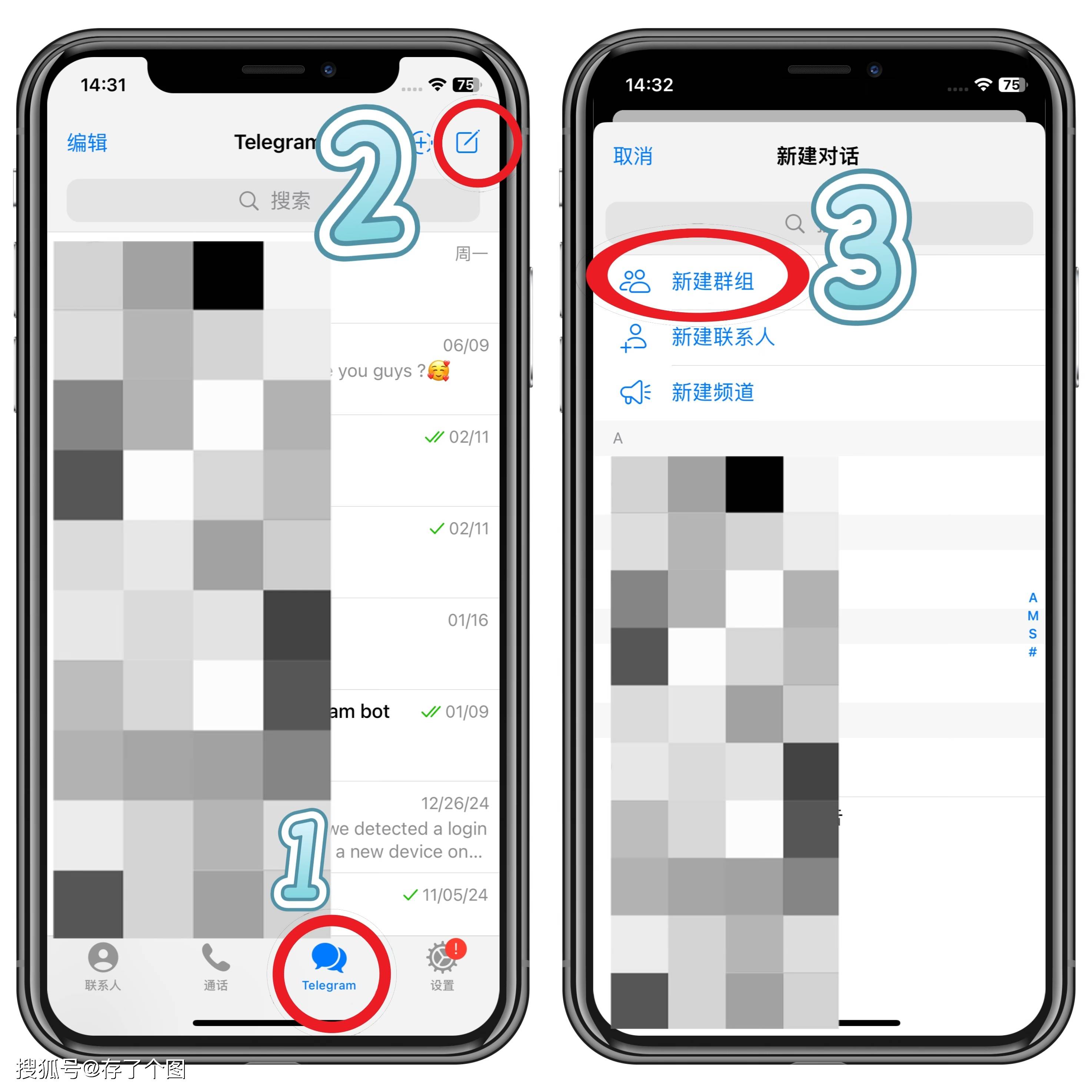
总结
北京美洽和成都美洽是一次全面性的重大升级,无论是在功能、界面还是性能方面都有显著提升。特别是智能文件夹管理和增强型隐私保护功能,将为用户带来更加便捷和安全的通讯体验。
建议所有用户尽快更新到最新版本,以体验这些令人兴奋的新功能。美洽资讯网将持续为您带来美洽最新资讯和使用技巧,敬请关注。